TDengine在SCARM云设备服务平台的使用
2020-03-03
设备监测与预测性维护业务场景介绍
设备预测性维护是在物流装备/机台等生产设备上加装物联网传感器,实时采集设备运行过程中的状态数据,运用边缘端/云端的设备维保知识库,管理设备维保作业,预警设备故障发生风险;形成物联采集端--边缘计算端—云端大数据端的管理闭环。这个闭环产生的行业价值是巨大的:
1、按计划保养设备,有效延长设备使用寿命;
2、预警设备故障风险,保障生产安全;
3、提供远程故障诊断工具,沉淀维保经验到知识库,为设备厂商创造增值服务,指导第三方维保服务;
4、量化管理维保作业,为第三方维保服务质量提供管理依据;
5、运用实时监控和数据分析等技术手段,借助边缘策略,及时处理现场宕机、来料短缺等突发情况。
SCARM是科大智联开发的远程监控与维护管理平台。运用物联网技术,实时监控堆垛机、穿梭车、提升机等物流设备的运行状态,结合维保作业管理数据,计算设备故障风险,指导用户采取适当措施排除设备故障风险,降低设备由于维护不当所致的停机风险。
实现目标如下:
1、 采集和存储堆垛机、穿梭车、提升机等设备实时运行数据;
2、 实时展示储堆垛机、穿梭车、提升机等运行情况,比如电机的电压、电流、行走速度、异常噪音等;
3、 预防性维护,综合分析设备运行与维护作业数据,推算设备故障风险;
4、 按期生成检查和维护保养计划,管理维保作业,保障生产安全。
设计系统的业务流程
SCARM是典型的物联网应用,边缘计算节点推送的数据经消息队列分发给流式计算模块及日志存储模块,物化模型与以关系数据库为中心的模型有很大区别,开发团队在评估不同的物联网开发框架后,选用了TDengine。我们以一个例子来展示TDengine简单易用的编程接口,及如何用它解决物联网特有的流式计算问题。例子的编程思路如下:
1、 采集服务采集设备数据,并传递到MQTT Server进行数据推送。
2、 数据处理服务订阅MQTT Server的最新数据,进行协议解析,将具体的字段进行处理,并调用TDengine的 JDBC标准接口写入数据。
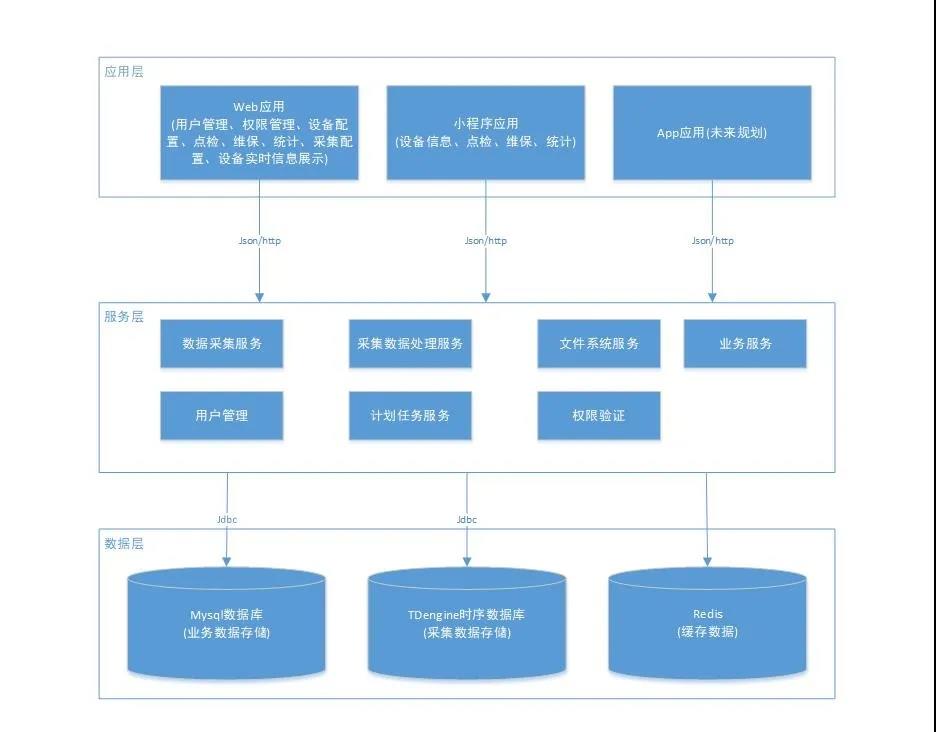
3、 再往上的架构就是标准的MVC架构:应用层调用服务层获取到数据层(TDengine时序数据库)中设备的统计及分析数据,并返回进行展示和操作。通过Grafana直接连接数据层TDengine数据库,在应用层展示设备的实时数据情况。
4、 这里需要注意的是,TDengine是一个设备一张表的设计思路,因此在步骤2的数据处理服务中,我们根据项目及设备类型在TDengine时序数据库中先建好超级表(每类设备一个超级表,定义好该类设备要采集的字段,以及一些静态标签如设备ID、分组等)和每个设备对应的子表。在MQTT协议解析后,每台设备的数据应存到其对应的子表中。子表的名字和设备ID之间要建立一种映射关系,这样在写入数据时可以根据上报数据中的设备ID信息直接找到要写的表名。当然整个平台的业务数据还是存储在关系数据库MySQL中;一些用户最常用的数据我们也放到了Redis中。TDengine可以解决最新采集数据的缓存问题,省去了一些Redis的内存开销。
系统的整体架构如下图:
TDengine配置使用
1、安装和配置TDengine数据库集群
在一台Linux服务器上安装TDengine的过程非常简单,只需要执行install.sh脚本,然后执行命令启动taosd服务即可(更多可参考 TDengine官网):sudo systemctl start taosd.
配置数据库集群
项目中采用3台服务器配置TDengine数据库集群。TDengine的分布式架构中分为虚拟数据节点和虚拟管理节点两种不同的虚拟化节点。虚拟节点是对物理服务节点的虚拟化分,其中数据节点的分布是完全去中心化的,而管理节点则是遵循Master-Slave的方式。因此再集群配置时,要配置一下管理节点主节点所在服务器的IP地址(MasterIP),以及第一备选节点的IP(SecondIP)。首先在3台服务器均完成TDengine安装后,先不要启动服务,在每台服务器的taos.cfg文件中添加MasterIP、SecondIP以及PrivateIP的配置信息。之后,启动3台服务器上的taosd服务,并用taos客户端连入主节点所在服务执行create dnode <DataNodeIP>。
其中<DataNodeIP>是具体的第二台服务器的通信IP地址。这样这台服务器就被加入到了集群中。
仿照上述操作配置第三台服务器后,通过show dnodes命令可查询配置的集群节点如下:

到此,集群配置成功。
2、 创建Spring Boot项目,配置taos依赖及参数
在SpringBoot项目的pom.xml文件中加入taos的jdbc依赖是
1. <dependency>2. <groupId>com.taosdata.jdbc</groupId>3. <artifactId>taos-jdbcdriver</artifactId>4. <version>1.0.1</version>5. </dependency>
在SpringBoot项目的.yml文件中配置公共的taos数据库连接url
1. spring2. taos:3. enable: true4. jdbcUrl: jdbc:TAOS://192.168.12.238:6020/demo?user=root&password=taosdata5. database: demo
3、 实现taos相关业务
打开taos数据库连接
1. try {2. if(connection == null)3. connection = DriverManager.getConnection(url);4. }catch (Exception e){5. e.printStackTrace();6. }
创建超级表及设备的子表
1. Statement smt = connection.createStatement();2. String sql = String.format(CREATE_SUPER_TABLE, s_name);3. smt.executeUpdate(sql);4.5. sql = String.format(CREATE_TABLE, t_name, s_name, paras[0], paras[1]);6. smt.executeUpdate(sql);
设备信息的插入
1. Statement smt = null;2. try{3. smt = connection.createStatement();4. return smt.executeUpdate("import into " + sqlBody);5. }catch (Exception e){6. e.printStackTrace();7. }finally {8. try {9. if(smt != null)10. smt.close();11. }catch (Exception e){12. e.printStackTrace();13. }14. }
设备信息的查询
1. Statement smt = null;2. List<T> list = new ArrayList<>();3. try{4. smt = connection.createStatement();5. result = smt.executeQuery(sql);6. Field[] fields = clazz.getDeclaredFields();7. T t = null;8. while (result.next()){9. t = clazz.newInstance();10. for (Field field : fields){11. field.setAccessible(true);12. field.set(t, result.getObject(field.getName(), field.getType()));13. }14. list.add(t);15. }16. }catch (Exception e){17. e.printStackTrace();18. }finally {19. try{20. if(smt != null)21. smt.close();22. }catch (SQLException se){23. se.printStackTrace();24. }25. }
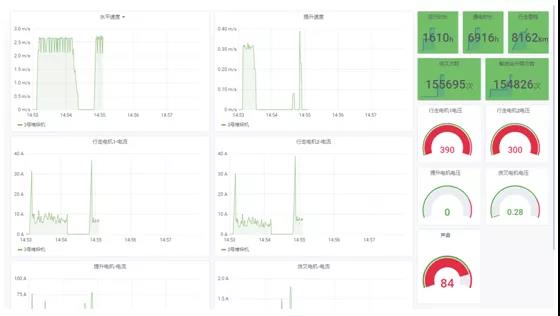
4、配合Grafana的可视化展示
实际效果图如下图:
使用TDengine的体会
相比关系型数据库,时序数据库对量级庞大的时序数据能高效的进行存储和查询,而且在存储空间的节省上也有很大的优势。特别是使用TDengine数据库,相较于一开始使用的OpenTSDB时序数据库,在I/O的操作会更快,数据存储空间占用少。再加上TDengine数据库的轻量、集成简单的优势,使用方式灵活,可发挥空间很大。后续期望能通过数据库自带的流式计算来分担业务上的一些计算压力。
科大智能物联技术有限公司
科大智能物联技术有限公司作为科大智能科技股份有限公司(股票代码:300222)的重要成员,是面向工业智能物联解决方案的先驱者和领军企业。公司在“引领行业发展,促进工业进步”的愿景下,秉承“创造价值、交付价值”的经营理念,致力于将智能算法、大数据技术、物联网技术等应用在物流与供应链、生产工艺优化、智能加工、产品质量检测与追溯等工业生产的不同领域和环节,将新技术赋能各类制造业企业,实现智能制造,提升客户企业竞争力,推动行业转型升级。
-
上一篇
热门动态
-
全球首创!重型钢管智慧物流仓储示范中心标杆项目成功落地
2026-05-13
-
政企链三方携手,科大智联大湾区总部落户江门共建制造业数字化新高地
2026-05-28
-
WEPACK见证:科大智联以“全链协同”加速印包行业迈入“智造时代”
2026-04-17
 分享到微信
分享到微信 分享到微博
分享到微博
电话: 0551-63666396
邮箱: service@aimstek.cn

合肥
合肥市蜀山区望江西路900号中安创谷A1栋 6F-7F
电话:0551-6366 6396
邮编:230088
上海
上海市泗砖公路777号
电话:021-3783 6988
邮编:201619
张家港
江苏省张家港市南丰镇永联小镇北街永琪园 1 幢
电话:0512-5890 0589
邮编:215600
皖ICP备18023965号-7 | Copyright © 2016-2022 科大智能物联技术股份有限公司 All Rights Reserved.